
美陆军智能化指挥系统技术研发
军工资源网 2022年06月30日2007年,美国DARPA开始资助推进“深绿计划”,目标是改进美陆军的旅级C4ISR系统,提高指挥官“观察-判断”(OODA前两步)效率,更直观展示不同决策下可能出现的战场结果。“深绿计划”的具体主要功能是协助指挥官创建行动指令(Courses of Action,COA),填补行动细节、开发替代方案以及评估决策对整个作战计划带来的影响。
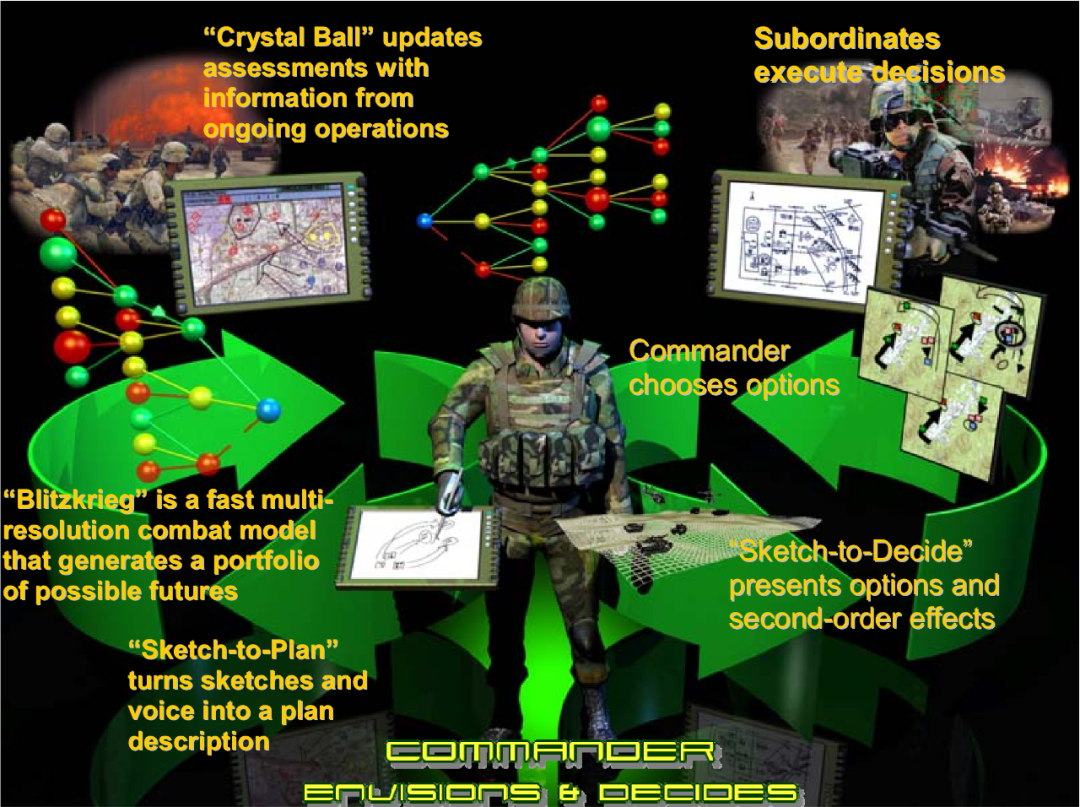
“深绿计划”基本原理是将各部队的“选项草图”的排列组合在一起,有可能产生许多不同结果的战场预测。这些可能的预测会被编制成一个“类图表”的结构,指挥官基于此探索更多未来可能,进行“假设”作战演练,随即生成更多可能的战场预测。“深绿计划”从正在发生的战场信息中提取有效信息,计算评估未来不同战场发展方向的概率,裁剪掉不太可能发生的情况后,帮助指挥官更加聚焦于更大概率发生的战场场景,确保指挥官不会面临无从选择的情况。
“深绿计划”主要有三个部分组成,分别是“闪电战”(Blitzkrieg)、“水晶球”(Crystal Ball)和“指挥官助手”(Commander’s Associate)。
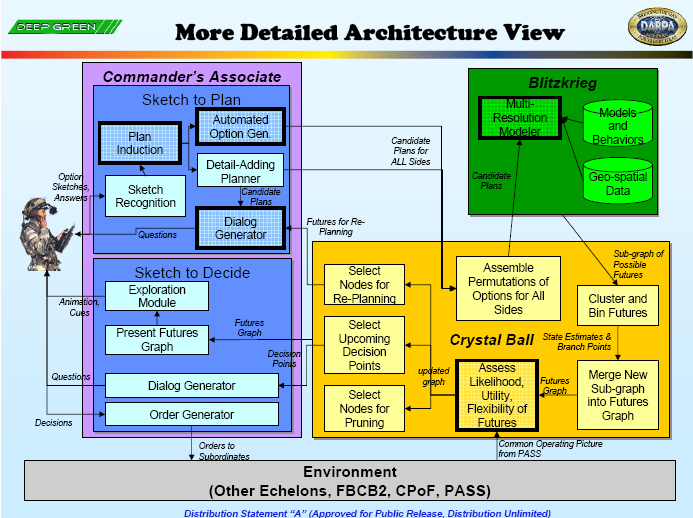
“闪电战”部分主要用来实现的分析功能,通过自动化的分析工具对采集的战场数据进行定量和定性的分析,生成可能出现的一系列未来结果,有些结果甚至超出人们最初的考虑范围。随着时间的推移,闪电战应该学会根据所提供的选项更好地预测可能的未来。“闪电战”可以识别各个分支点,分别预测可能产生的结果,并计算每个结果的可能性,然后继续沿着每个路径进行模拟。“闪电战”具有一定的创造性思维,不仅仅是简单输出数百或数千次随机模型的“蒙特卡罗”运行结果。
“水晶球”部分则是用来实现系统的总控功能,主要功能包括控制“闪电战”的运行;根据采集的战场信息,对战场的实时态势进行更新;利用采集的信息更新战场态势,方便指挥员在“草图”上进行下一步规划;向指挥员提出优先选项。
“指挥官助手”有两个主要的子部分,“草图到计划”(Sketch to Plan)和“草图到决定”(Sketch to Decide)。“草图到计划”为指挥官提供了快速生成定性、粗颗粒度的作战方案(COA)草图的能力;当指挥官绘制草图时,计算机将观察草图的绘制,并监听指示顺序、时间、意图等的关键词,从草图和关键词中归纳出计划和指挥官的意图。“草图到决定”是向指挥员提供未来可能的选择和更新。
“深绿计划”的重点是成为一个帮助指挥官快速生成决策选择的工具(虽然指挥官通常不希望机器生成行动方案)。DARPA对“深绿计划”的愿望是将大量计算和预测工作转为让人工智能机器来进行,更进一步提高效率和准确性,帮助指挥官加快战场决策节奏,但是到2014年验收时,实际可使用的只有“草图到计划”功能。“深绿计划”所面临的问题是计算机究竟能否理解战场的实时态势,决策所依据的信息是否真实、是否全面、是否可量化,最困难之处还是对敌方的决策如何假定。“闪电战”的推演功能也存在推演偏离度过大的问题,其鲁棒性值得怀疑,并且敌方的作战决策也在不断调整,反身性的也同样影响到“闪电战”的推演结果。
2016年,美陆军通信与电子研究、开发和工程中心(CERDEC)启动了“指挥官虚拟参谋”项目,目的是采用工作流和自动化技术帮助营级指挥官和参谋监控作战行动、同步人员处理、支持实时行动评估。2018年,“指挥官虚拟参谋”完成了工作流程结构组建工作,并实现了任务自动化概念验证。

“指挥官虚拟参谋”借鉴了美国苹果公司Siri、谷歌公司Google Now等人工智能语音系统产品的思路综合应用认知计算、人工智能和计算机自动化等智能化技术,来应对海量数据源及复杂的战场态势,提供主动建议、高级分析及针对个人需求和偏好量身剪裁的自然人机交互,从而为陆军指挥官及其参谋制定战术决策提供从规划、准备、执行到行动回顾,全过程的决策支持。根据美陆军CERDEC所说,“指挥官虚拟参谋”将利用自动化和认知计算技术来应对战场上大量的数据源和高度复杂的态势,从而作为“参谋”帮助指挥官做出更准确的决策。因此,“指挥官虚拟参谋”具有数据聚合、集成敏捷规划、计算机辅助运行评估、基于事件的当前任务和态势的持续预测等功能。
(1)数据聚合:通过与现有指挥系统的接口提供数据聚合,以根据需要整合和调解来自参谋计算机系统、传感器或前线士兵的数据信息,并为指挥官提供聚合数据收集;
(2)集成敏捷规划:支持战争博弈、准备、排演,及实现任务执行过程中的人机协作;
(3)计算机辅助运行评估:基于当前、未来及替代方案等,向指挥员持续提供计算机支持的在线评估;
(4)持续预测:基于态势数据和当前计划,识别和推理态势的演变,生成告警,和具有一定置信度的未来态势图。
“指挥官虚拟参谋”运用了机器学习和用户配置算法,系统行为可以在机器学习训练期间或实际应用期间随时调整。“指挥官虚拟参谋”的目标包括学习和识别用户行为习惯,测试和更新敌人战术模型以及本地环境。通过学习经验丰富的指挥官的行为决策习惯,形成珍贵的数据记录,最终可以生成供新指挥官参考使用的知识、作战过程和作战经验。
“指挥官虚拟参谋”项目是美陆军后方研究人员为指挥官提供指控支持的长期愿景的一部分,并且直接支持美陆军2020~2040作战概念,作为陆军执行任务指挥、增强态势理解、优化人员绩效、协助培养未来指挥官的关键技术支持。可以看出,“指挥官虚拟参谋”大量借鉴了美陆军之前的研究积累,就包括“深绿计划”的研究成果。CERDEC将“指挥官虚拟参谋”项目打造为一个开放式架构平台,可以与其他CERDEC或美国防部S&T平台融合,还可以作为孵化器开发一系列有用的数字决策支持功能。
2018年5月,美陆军训练与条令司令部宣布,多域战概念正式转变为多域作战;同年12月,美陆军训练与条令司令部发布《2028多域作战中的美国陆军》,将多域作战概念写入条令。多域作战具有作战领域多域化、作战要素融合化、作战编成弹性化、作战体系去中心化等特点,因此传统的指挥控制经典理论已经难以适应多域作战的指挥控制。
2021年5月,美陆军研究实验室(Army Research Laboratory)发布了《面向多域作战(MDO)指挥控制(C2)的人工智能(AI)》倡议文件,指出美陆军在2035年的多域作战行动中,需要具备敏捷、自适应的人工智能指挥控制系统,以快速同步多个作战行动。该系统可在复杂、快节奏和极度活跃的多域作战中提供作战规划和决策支持功能,能够分析敌方的活动;通过不断地感知、识别和快速利用新出现的优势窗口,持续对战役进行规划、准备、执行与评估,从而使美陆军的各种能力能够快速响应。随着近些年来基于深度增强学习(Deep Reinforcement Learning)算法的发展,在多个战略类型游戏中已经展现出了实力,未来在多域作战指控领域有巨大的应用潜力。
美陆军研究实验室还提出了一项“人工智能多域作战指控应用”的指挥官战略倡议(“AI for C2 of MDO” Director’s Strategic Initiative),目标是探讨了基于深度增强学习算法可用于评估红军状态、评估红蓝军战斗损失、预测红军的战略和行动、基于所有情况制定蓝军计划的能力水平。采用基于深度增强学习算法的人工智能技术,有可能为蓝军制定更具有创新性的作战计划,可以比经验丰富的军官更快的抓住潜在机会窗口。在倡议中,美陆军研究实验室探索性的使用深度增强学习算法在作战行动之前制定详细计划,并在执行期间生成实时计划和建议。主要目标是验证:基于深度增强学习算法的概念化设计和实施,看是否能够生成与军事指挥官一致的作战计划(或更优化的作战计划);将“人”纳入“命令和学习循环”,并评估这些“人在回路”(Human-in-the-loop)解决方案。
从美陆军指挥控制系统的智能化成果上可以看出,这些指控系统主要针对的是战术级指挥,基本还是基于OODA模型方法,重点在战场态势的自主研判及预测运用、情报侦察智能分析、作战筹划智能决策、作战过程精确描述、敏捷响应等方面。2019年,美军提出了“马赛克战”概念,融合了作战云、多域作战、忠诚僚机等理念,更加需要依赖高度智能化的指挥控制系统。为适应未来无人/有人协同的路战场环境,美陆军十分重视人工智能在指挥控制领域的应用,不仅在战术层面,更加注重在战略层面通过计算推演提高战场态势认知、判断、决策,并且还能够同步实现火力网的智能化指令控制。目前,美国谷歌公司旗下的DeepMind开发的“Alpha”系列人工智能产品已经具备自我博弈对抗学习、人机博弈对抗学习的能力,并且开始在美陆军指控系统中试验性应用。(北京蓝德信息科技有限公司 研究员 米佩琛)